Building runtime-controlled AI agents
We've all seen what happens when you give an AI agent free rein. It drifts, loses its mind, and goes rogue, burning through your API budget. Not always because the model is bad, but because nothing is keeping it in bounds. So I wanted to see what happens when an AI agent isn't allowed to act like one big general-purpose coding assistant. To test this, I built an experiment where the LLM is stripped of its autonomy and forced to operate inside a small runtime.

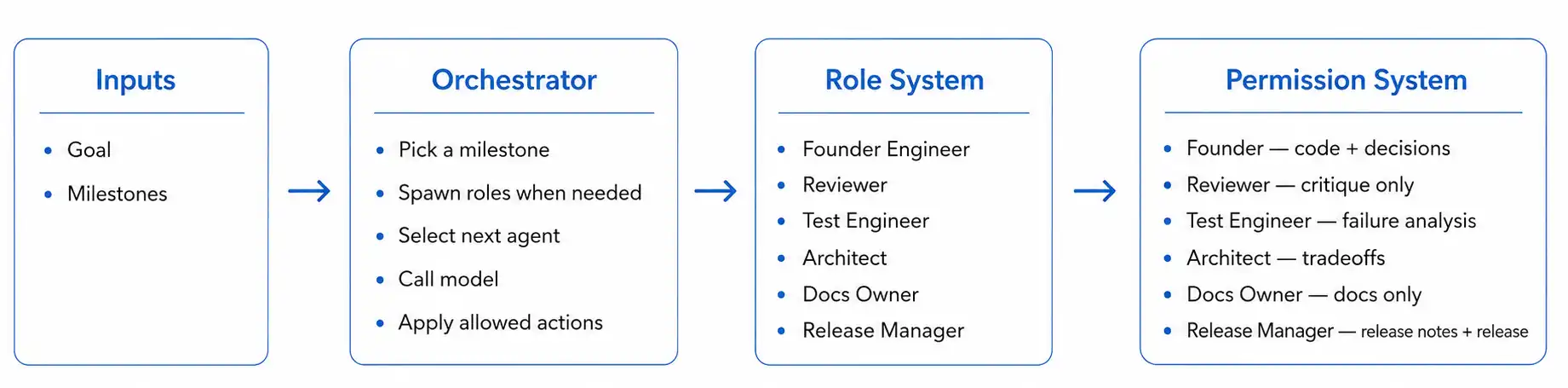
Architecture
The runtime creates a small workspace and asks agents to build an issue tracker, where users can create issues, search through them, and add or remove labels, across five fixed milestones. Each milestone has acceptance criteria, and the project can only move forward when an allowed agent closes the current milestone. The important part is that the model does not directly own the project. It proposes actions, and the runtime decides which actions are allowed.
export const milestones: Milestone[] = [
{
...
acceptanceCriteria: [
'Create a small TypeScript app structure.',
'Add a README that explains what this project is and is not.'
]
},
{
...
acceptanceCriteria: [
'Define an issue model.',
'Add simple local persistence.'
]
...
Hardcoding these milestones explicitly prevents the model from inventing its own roadmap. When the model owns the plan, it tends to expand the scope or finish too early.
The system starts with one agent: the Founder Engineer, who owns the product progress. Additional agents appear only when the runtime sees enough pressure to justify another.
The agents that can be created by the runtime are:
- Founder Engineer: writes code and owns milestone progress.
- Reviewer: critiques changes.
- Test Engineer: looks for failures.
- Architect: records tradeoffs.
- Doc Owner: writes documentation.
- Release Manager: writes release notes and closes the release.
Each role has a different permission set.
Each run has the mission, current milestone, active agents, changed files and, completed milestones.
if (!permission.allowed) {
printEvent(addEvent(
world,
'error',
`Action rejected: ${agent.name}`,
permission.reason,
agent.id,
{
actionType: action.type,
path: action.path ?? undefined,
role: agent.kind
}
));
return;
}
The timeline is just as important as the generated files. Each action is stored and can be inspected to find out which agent acted, what it tried to do, what was accepted/rejected, and why milestones were closed.
The model proposes actions, but the runtime owns the policy.
Agent spawning
The first version had only the founder agent. It completed all milestones by itself, which produced no real engineering process.
The next iteration allowed the founder to propose new agents. This didn't work well either. The founder rarely proposed review or testing. If the same agent that writes the code is also deciding whether the code needs review, it will just keep moving.
So that decision had to move into the runtime. The runtime can spawn roles when simple thresholds are crossed. A reviewer appears after enough files are written or after the first milestone is completed. A tester appears after the project has enough activity. An architect appears when design decisions are pending. A Doc owner appears once the project has enough implementation. A release manager appears near the end, when the prototype needs release judgment.
if (role === 'reviewer' && (fileWrites >= 2 || milestoneCount >= 1)) {
return { allowed: true, reason: 'Time for review.' };
}
if (role === 'tester' && (fileWrites >= 3 || milestoneCount >= 2)) {
return { allowed: true, reason: 'Time for testing.' };
}
...
Orchestrator
The orchestrator is the pilot: it owns the loop, the model calls, execution, spawning, and error handling. The runtime picks the active agent, gives them the current milestone, accepts structured actions and saves the state. The model can only reason inside a narrow box and the box belongs to the orchestrator.
Scheduling
The scheduler decides which agent should act next based on the current milestone. It is based on the current milestone as we don't want the agent acting before there is anything useful to do for them. Once the files change, the reviewer gets the work. Later milestones give the tester a turn after files change, and the docs owner is introduced only when documentation work make sense.
function selectAgent(world: WorldState): Agent {
...
if (reviewer && !hasRoleTurnAfterFirstFileWrite(world, 'reviewer')) {
return reviewer;
}
if (tester && world.currentMilestoneIndex >= 1 && !hasRoleTurnAfterFirstFileWrite(world, 'tester')) {
return tester;
}
...
This is a different model from "agents talking to each other". The system is closer to a sequence of passes over the same work.
Permissions
In the early version, every agent could perform every action. That made the role system meaningless. A tester who can write code is just another engineer. So I added an explicit permission layer.
const rolePermissions: Record<AgentKind, RolePermission> = {
founder: {
canWriteFiles: true,
writablePaths: [...],
canRecordDecision: true,
canProposeAgent: true,
canCompleteMilestone: true
},
reviewer: {
canWriteFiles: false,
writablePaths: [],
canRecordDecision: true,
canProposeAgent: true,
canCompleteMilestone: false
},
The permission system produced some of the best events in the run. In one run, the reviewer tried to complete a milestone, the action was rejected and logged. The rejection is the point of the system.
Model
The agents return JSON using OpenAI, with a strict JSON schema, and they are validated locally using zod.
The model receives the active role, current milestone, acceptance criteria, recent decisions, active agents etc. It is also necessary to cap output size because unbounded file generation is an easy way to burn money. Another constraint is catching empty or malformed data from the model. Retrying the same turn is also a billing bug.
Observation
One run completed all five milestones.


Spawn proposals: 0 is worth paying attention to. The agents did not invent the organization, the runtime introduced roles when thresholds were crossed. That specialization changed the output. The reviewer caught a missing entry point. The tester kept finding weak input validation. The architect flagged migration risk around file storage. The docs owner updated the README.md after implementation was complete. The release manager wrote the release notes with known limitations. None of these is a profound discovery. They are exactly the kind of problems a senior engineer would expect in a prototype.
Final Thoughts
The generated issue tracker was not the impressive part. The process around it was. Calling a model with six different prompts is easy, but making those roles behave like an engineering process is harder. The runtime has to decide which role acts next, what counts as review, when new roles should appear and when the run should stop.
The next version should add verification to the milestone gate. The runtime should run the generated project, and the milestone completion should require a passing build. This keeps the boundary clean: models generate and reason over proposed changes, while the orchestrator checks reality and enforces policy.
There is also the larger lesson from this experiment. Prompts can describe roles, but the runtime has to enforce them. If roles are not constrained by the runtime, every role becomes the same general-purpose coding assistant.